Keras+CNNでCIFAR-10の画像分類 その3
今回は前回使ったモデルをチューニングし、CIFAR-10の認識精度を向上させた。 モデルのパラメータ変更の他、BatchNormalizationも試みたところ、 前回の78%だった認識精度を85%まで上げることができた。
なお、本記事には何かをまとめる意図は無い。 とりあえずやってみたことをダラダラ書き連ねる単なる実験ノートである。 やったことも割と当てずっぽうだし、特にそれといった考察もしない。
1. 事前準備
いつもの。
# Matplotlib
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
# Numpy
import numpy as np
# Keras
import keras
from keras import backend as K
from keras.datasets import cifar10
from keras.models import Model, Sequential
from keras.layers import Dense, Dropout, Flatten, Activation, Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.utils import plot_model
from keras.preprocessing.image import ImageDataGenerator
# グローバル設定
img_rows, img_cols, img_channels = 32, 32, 3
num_classes = 10
batch_size = 64
# データセット読み込み
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
トレーニングセット、テストセットは事前に全部まとめてZCA白色化した。 ZCA白色化自体については前回、前々回で記事にした。
train_datagen = ImageDataGenerator(zca_whitening=True)
train_datagen.fit(x_train)
train_generator = train_datagen.flow(x_train, y_train, batch_size=len(x_train))
x_train_pca, y_train_pca = train_generator.next()
test_datagen = ImageDataGenerator(zca_whitening=True)
test_datagen.fit(x_test)
test_generator = train_datagen.flow(x_test, y_test, batch_size=len(x_test))
x_test_pca, y_test_pca = test_generator.next()
あと、学習曲線をプロットする関数も作っておいた。
def plot_loss(hist):
plt.clf()
plt.xlabel('epochs')
plt.plot(np.arange(1, len(hist.history['loss'])+1),
hist.history['loss'], label='loss')
plt.plot(np.arange(1, len(hist.history['loss'])+1),
hist.history['val_loss'], label='val_loss')
plt.legend()
return plt
2. モデル2 畳み込み4層, 全結合層2層, 学習減衰率1e-4
モデルはこれまでと同じ。
AdaDeltaなので多分意味は無いが、Optimizerに学習減衰率を設定してみた。
def make_model2():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
strides=(1, 1), padding='valid',
activation='relu',
input_shape=(img_rows, img_cols, img_channels)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(decay=1e-4),
metrics=['accuracy'])
return model
model = make_model2()
hist = model.fit(x_train_pca, y_train_pca, batch_size=batch_size,
epochs=80,
validation_split=0.1,
verbose=1)
認識精度はいきなり82%出た。
80エポック回した成果か、学習減衰率の設定が効いたのかわからない。
scores = model.evaluate(x_test_pca, y_test_pca)
print('loss={}, accuracy={}'.format(*scores))
# loss=0.773371640205, accuracy=0.8159
plot_loss(hist).savefig('loss_model2.png')
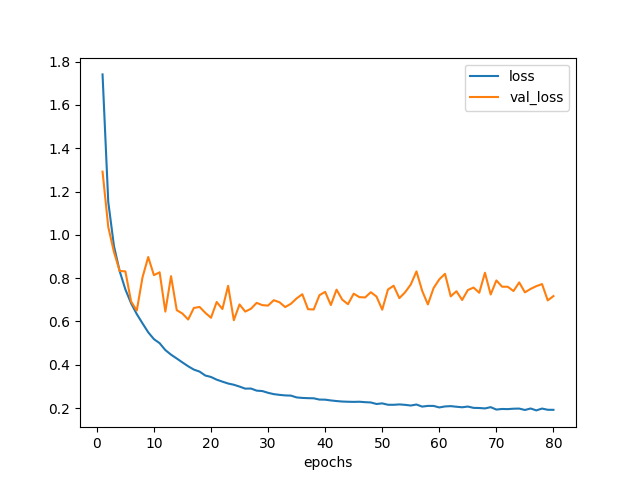
図2.1. 学習曲線 モデル2
3. モデル3 畳み込み3,4層チャンネル数増量拡大版
畳み込み層の3, 4つ目のチャンネル数を64から128に増やしてみた。
def make_model3():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
strides=(1, 1), padding='valid',
activation='relu',
input_shape=(img_rows, img_cols, img_channels)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(decay=1e-4),
metrics=['accuracy'])
return model
model = make_model3()
hist = model.fit(x_train_pca, y_train_pca, batch_size=batch_size,
epochs=80,
validation_split=0.1,
verbose=1)
結果、認識精度82%になった。精度向上には結びつかなかったようだ。
scores = model.evaluate(x_test_pca, y_test_pca)
print('loss={}, accuracy={}'.format(*scores))
# loss=0.824766657305, accuracy=0.8178
plot_loss(hist).savefig('loss_model3.png')
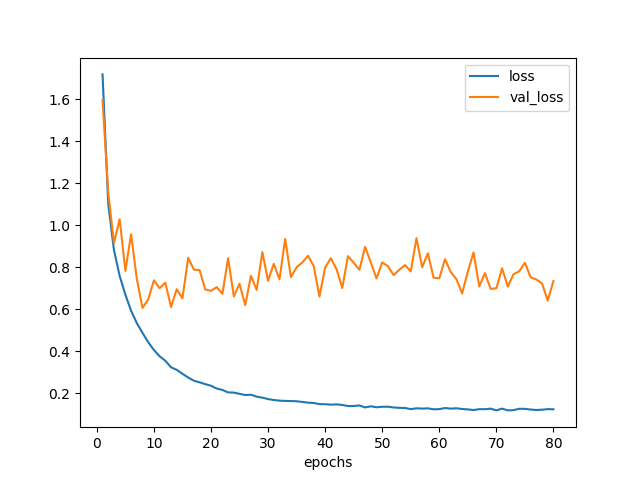
図3.1. 学習曲線 モデル3
モデル4 ドロップアウト率増加
割と過学習しがちな気がしたのでドロップアウト率を増やしてみた。 ドロップアウトが多くなると当然学習が進みにくくなるので、エポック数も2倍に増やしてみた。
def make_model4():
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3),
strides=(1, 1), padding='valid',
activation='relu',
input_shape=(img_rows, img_cols, img_channels)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
return model
model = make_model4()
hist = model.fit(x_train_pca, y_train_pca, batch_size=batch_size,
epochs=160,
validation_split=0.1,
verbose=1)
結果は78%。これは違うかな。
scores = model.evaluate(x_test_pca, y_test_pca)
print('loss={}, accuracy={}'.format(*scores))
# loss=0.715044586468, accuracy=0.779
plot_loss(hist).savefig('loss_model4.png')
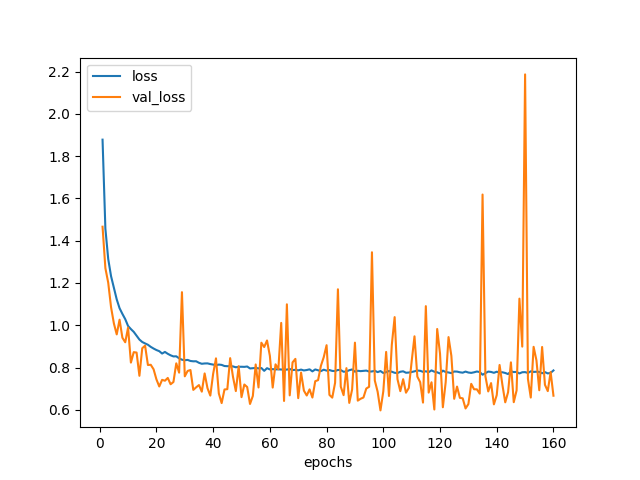
図4.1. 学習曲線 モデル4
モデル5 畳み込み2,4層後BatchNormalization
畳み込み層のあとに BatchNormalization を挿入してみた。 BatchNormalization は、ミニバッチ内でデータを変換し、 平均0、分散1へ正規化してあげる手法である。 多層のネットワークの後段における入力データの分布を正規化することにより、 学習が進みやすくなると考えられている。
def make_model5():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
strides=(1, 1), padding='valid',
activation='relu',
input_shape=(img_rows, img_cols, img_channels)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(decay=1e-4),
metrics=['accuracy'])
return model
model = make_model5()
hist = model.fit(x_train_pca, y_train_pca, batch_size=batch_size,
epochs=80,
validation_split=0.1,
verbose=1)
結果は認識精度83%になった。 これは効いていそうだ。
scores = model.evaluate(x_test_pca, y_test_pca)
print('loss={}, accuracy={}'.format(*scores))
# loss=0.738402506161, accuracy=0.8277
plot_loss(hist).savefig('loss_model3.png')
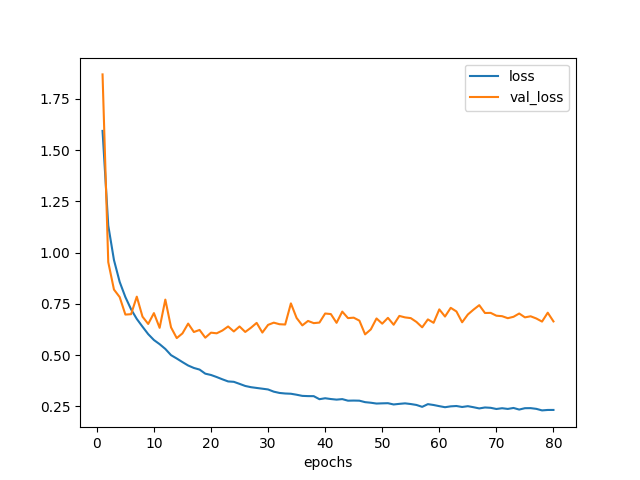
図5.1. 学習曲線 モデル5
6. モデル6 Conv2D+BatchNormalization
実は BatchNormalization は ReLU などアクティベーションの前で行うのがよいと言われている。 そこで各 Conv2D と ReLU の間に BatchNormalization を入れてみた。
def make_model6():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
strides=(1, 1), padding='valid',
input_shape=(img_rows, img_cols, img_channels)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(decay=1e-4),
metrics=['accuracy'])
return model
model = make_model6()
hist = model.fit(x_train_pca, y_train_pca, batch_size=batch_size,
epochs=80,
validation_split=0.1,
verbose=1)
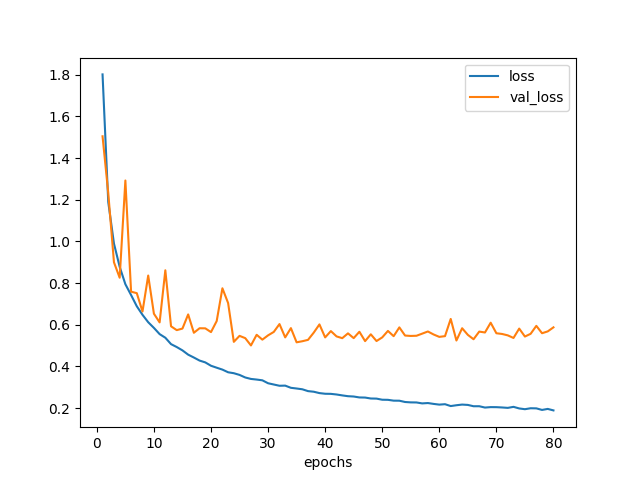
認識精度がさらに少し向上し、84%になった。
scores = model.evaluate(x_test_pca, y_test_pca)
print('loss={}, accuracy={}'.format(*scores))
# loss=0.637564155602, accuracy=0.8389
plot_loss(hist).savefig('loss_model6.png')
 ```
```
図6.1. 学習曲線 モデル6
7. モデル7 BatchNormalization + 畳み込み3,4層のチャンネル数増量版
BatchNormalization を挿入したことにより より多くのパラメータを学習できるようになったんじゃないかと思ったので、 畳み込み層のチャンネル数を増やしてみた。
def make_model7():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
strides=(1, 1), padding='valid',
input_shape=(img_rows, img_cols, img_channels)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(128, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(decay=1e-4),
metrics=['accuracy'])
return model
model = make_model7()
hist = model.fit(x_train_pca, y_train_pca, batch_size=batch_size,
epochs=80,
validation_split=0.1,
verbose=1)
結果は85%になった。やったね。
scores = model.evaluate(x_test_pca, y_test_pca)
print('loss={}, accuracy={}'.format(*scores))
# loss=0.692957502472, accuracy=0.846
plot_loss(hist).savefig('loss_model7.png')
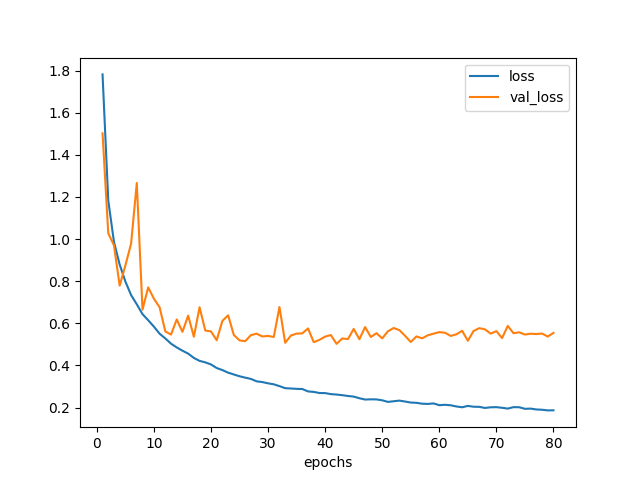
図7.1. 学習曲線 モデル7
8. モデル8 学習減衰率を無くしてみた版
そういえば学習減衰率の効果って結局どうなんだっけと思い、 AdaDelta のパラメータを戻してみた。
def make_model8():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
strides=(1, 1), padding='valid',
input_shape=(img_rows, img_cols, img_channels)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(128, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
return model
model = make_model8()
hist = model.fit(x_train_pca, y_train_pca, batch_size=batch_size,
epochs=80,
validation_split=0.1,
verbose=1)
認識精度84%。うーん、悪くなったか?
scores = model.evaluate(x_test_pca, y_test_pca)
print('loss={}, accuracy={}'.format(*scores))
# loss=0.996272477233, accuracy=0.838
plot_loss(hist).savefig('loss_model8.png')
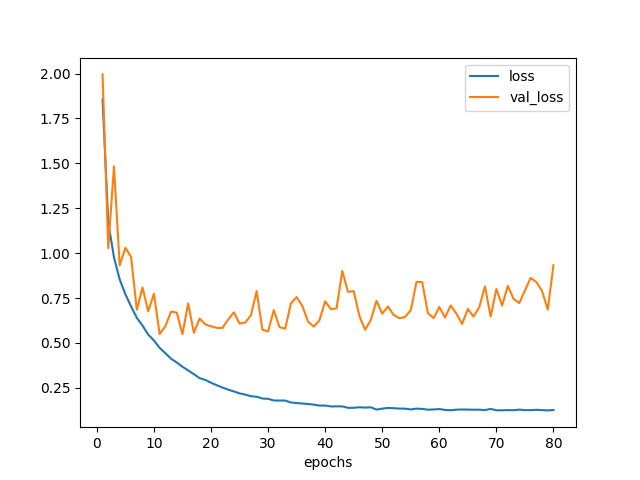
図8.1. 学習曲線 モデル8
9. まとめ
最高85%の認識精度が出た。
ZCA白色化する前だと74%だったので、ほぼ同じようなモデルを使っていても チューニングをするだけで10%以上の精度向上ができてしまった。
データの前処理、チューニングはとても重要である。