Keras+CNNでCIFAR-10の画像分類
前回までは MNIST の分類問題をやってみた。
今回からは CIFAR-10 の分類を使いもう何歩か CNN についての理解を深めていく。
本題に入る前に、そもそも CIFAR-10 って何だったか勉強しておこう。
1. CIFAR-10 について
CIFAR-10 and CIFAR-100 datasets
CIFAR-10 はラベル付き画像のデータセット。 Alex Krizhevsky、Vinod Nair、Geoffrey Hintonによって収集された。 とても聞いたことのある名前だ。
CIFAR-10 データセットには 60000 枚の画像が含まれており、 それらは全て 10 種類のクラスのいずれかに分類され、 全てのクラスに同じ枚数だけ、すなわち 6000 枚ずつ、の画像を入れている。 どれに分類されるかも勿論データセットに入っていて故にラベル付きである。 60000 枚の画像のうち、50000 枚が訓練用、残り 10000 枚がテスト用。
各画像は画素数 32x32 で RGB で彩色されている。
クラスには10種類があり、次の通り:
- airplane; 飛行機
- automobile; 自動車(トラック以外)
- bird; 鳥
- cat; 猫
- deer; 鹿
- dog; 犬
- frog; 蛙
- horse; 馬
- ship; 船, 舟
- truck; 大型トラック
また、データセットはいい感じにシャッフルされており、 順番に見ていくと各クラスはランダムに出現する。
Keras には CIFAR-10 を読み込むためのライブラリが入っているので、 それを使えば簡単にこのデータセットに対する学習が始められる。
from keras.datasets import cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data()戻り値 2つのタプル:
x_train,x_test:shape (num_samples, 3, 32, 32)のRGB画像データのuint8配列.y_train,y_test:shape (num_samples,)のカテゴリラベル(0-9の範囲のinteger)のuint8配列.
2. 前準備
はじめにライブラリのインポートとデータセットの読み込みをする。
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import numpy as np
import keras
from keras import backend as K
from keras.datasets import cifar10
from keras.models import Model, Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.utils import plot_model
img_rows, img_cols, img_channels = 32, 32, 3
num_classes = 10
batch_size = 64
# Load dataset
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('x_train.shape', x_train.shape)
# ('x_train.shape', (50000, 32, 32, 3))
print('y_train.shape', y_train.shape)
# ('y_train.shape', (50000, 10))
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
せっかくだから読み込んだ画像も見てみる。
LABELS = ('airplane', 'mobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse','ship', 'truck')
def index_to_label(idx):
if idx < len(LABELS):
return LABELS[idx]
else:
return None
def vector_to_label(v):
idx = np.argmax(v)
return index_to_label(idx)
plt.clf()
for i in range(0, 40):
plt.subplot(5, 8, i+1)
pixels = x_train[i,:,:,:]
plt.title(vector_to_label(y_train[i]), fontsize=8)
fig = plt.imshow(pixels)
fig.axes.get_xaxis().set_visible(False)
fig.axes.get_yaxis().set_visible(False)
plt.savefig('cifar10_image_train.png')
これは人間的にも結構難しそうだ。

図 2.1. CIFAR-10 の画像例
3. これまでと同じく学習してみる
とりあえず前回まで MNIST で使ったモデルを使ってみることにする。 それは以下のようなモデルだった。
ただし、input_shape のチャンネル数を 3 にして RGB 対応した。
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
strides=(1, 1), padding='valid',
activation='relu',
input_shape=(img_rows, img_cols, img_channels)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
いちおう可視化もしておく。
plot_model(model, to_file='model1.png', show_shapes=True)
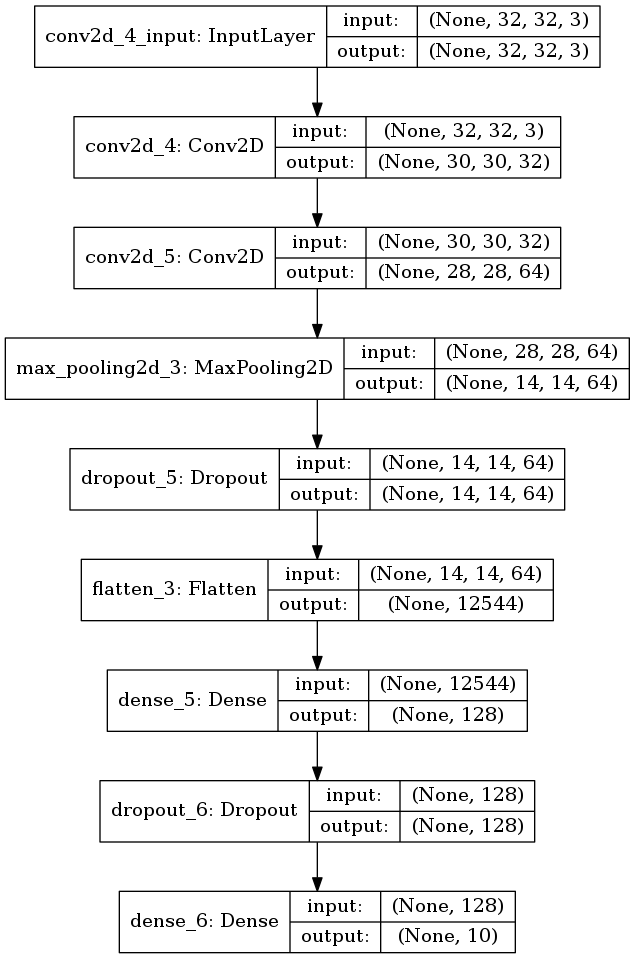
図 3.1. これまでと同じモデル
訓練する。
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
hist = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=20,
validation_split=0.1,
verbose=1)
scores = model.evaluate(x_test, y_test)
print('loss={}, accuracy={}'.format(*scores))
# loss=0.892580286503, accuracy=0.7171
精度71%。うーん、こんなもんなのか。
学習曲線も描いてみた。
plt.clf()
plt.xlabel('epochs')
plt.plot(np.arange(1, len(hist.history['loss'])+1),
hist.history['loss'], label='loss')
plt.plot(np.arange(1, len(hist.history['loss'])+1),
hist.history['val_loss'], label='val_loss')
plt.legend()
plt.savefig('model1-loss.png')
図 3.2. のようになった。
loss はエポックを重ねるごとに順調に下がっているものの、
val_loss は 3 エポック目くらいで下げ止まった。
これではエポック数を増やしても大した効果は期待できないだろう。
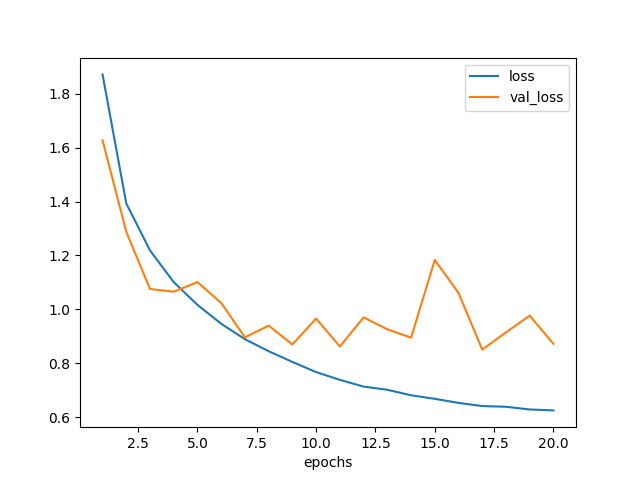
図 3.2. モデル1の学習曲線
せっかくなので認識結果も見てみる。
y_predicted = model.predict(x_test)
plt.clf()
for i in range(0, 40):
plt.subplot(5, 8, i+1)
pixels = x_test[i,:,:,:]
isok = np.argmax(y_test[i]) == np.argmax(y_predicted[i])
plt.title('{} {}'.format('o' if isok else 'x',
vector_to_label(y_predicted[i])),
fontsize=8)
fig = plt.imshow(pixels)
fig.axes.get_xaxis().set_visible(False)
fig.axes.get_yaxis().set_visible(False)
plt.savefig('cifar10-model1-predicted.png')

図 3.3. モデル1の認識結果
o が頭に付いていればあたり、x が付いていればはずれである。
犬や鳥を鹿と言ったり、鹿や蛙を猫と言ったりしてしまっているようだ。 確かにきわどいところはある。惜しい。
最下段、右から3番目あたりもトラックに見間違えても仕方なさそうだ。
左3上1の画像は飛行機のようだが、猫として分類されてしまっている。 でもこれは F-14 Tomcat では?そうだったらある意味あってるね。
あと、Softmax では確率に相当するものが出ているはずだ。 これもせっかくだから見ておく。 もしかしたら間違えている場合にも、 第1候補、第2候補を同じ位の確率で出しているかもしれない。
def print_predicted(i):
asc = np.argsort(y_predicted[i])
for j in range(0, 3):
idx = asc[-j-1]
print('{}: {:2.1f}%'.format(index_to_label(idx), y_predicted[i][idx] * 100))
| 画像 | 正答 | 1位 | 2位 | 3位 |
|---|---|---|---|---|
| 左1上1 | 猫 | 猫 74% | 鹿 22% | 犬 2.8% |
| 左1上2 | 猫 | 猫 82% | 鹿 12% | 犬 2.3% |
| 左1上3 | 犬 | 犬 92% | 猫 8.0% | 馬 0.1% |
| 左1上4 | 犬 | 鹿 97% | 犬 1.2% | 鳥 0.7% |
| 左1上5 | 鹿 | 鹿 65% | 鳥 29% | 蛙 3.9% |
期待と異なり、自信満々で間違えていた。
表にした範囲だと、胴が写っている動物は結構なんでも鹿に見えてしまうのかもしれない。
4. まとめ
CIFAR-10 は MNIST と比べると認識が難しい。 MNIST で 99% 正解できるモデルを持って来てそのまま CIFAR-10 を学習させても 71 % しか正答率が出なかった。
難しさの理由は、分類するために学習しなければいけない特徴が CIFAR-10 の方がより複雑なためだと想像できる。
複雑な特徴を学習する方法として、ネットワークモデルを工夫するという手は当然あるが、 前処理をうまくやるとそのままのモデルでも学習能力が上がったりするらしい。
そこで次回はオリジナルデータに対して前処理を実行してみて、 結果がどう変わるか実験してみたいと思う。