Keras+VGG16でImageNetの画像分類
今回は VGG16 を試してみる。 入門編ということで単に Keras から VGG16 を利用する方法を学ぶ。
これまでの Keras シリーズは以下。
- Keras+CNNでCIFAR-10の画像分類 その1
- CIFAR-10のPCA白色化/ZCA白色化
- Keras+CNNでCIFAR-10の画像分類 その2
- Keras+CNNでCIFAR-10の画像分類 その3
1. VGG16
VGG というのは、Visual Geometry Groupの略らしい。
オックスフォード大学で深層学習を使った画像認識を研究しているグループのようだ。
VGG16 というのは彼らが作った有名な多層ニューラルネットで、VGG_ILSVRC_16_layersとしても公開されている。 畳み込み13層、全結合層3層で計16層あるネットワークで VGG が考案したものなので VGG16 と呼ぶようだ。
VGG16 で扱う入力は 224x224 の RGB カラーの画像である。
2. ImageNet
ImageNet で訓練済みの VGG16 重みデータが VGG により公開されており、 Keras ライブラリでもそれを簡単にロードして使う機能がある。
ImageNet は画像のデータセット(またはそれを収集するプロジェクト)で、 現時点で 1,400 万枚の画像があるらしい。
3. 事前準備
いつもの。 今回は自分でモデル構築をしないので少なめ。
# Numpy
import numpy as np
# Matplotlib
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
# Keras
from keras.utils import plot_model
あとで動作確認用に独自に用意した画像を認識させてみるため、
Keras の image ライブラリをロードし、読み込み用の関数を作った。
from keras.preprocessing import image
def load_image(filename):
img = image.load_img(filename, target_size=(224, 224))
return image.img_to_array(img)
さらに VGG16 関係のライブラリをインポートする。
# Keras VGG16
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
4. VGG16 のモデルと重みのロード
VGG16 のモデルと重みをロードする。
以下のコードを実行するだけでモデルと、 ImageNet 向けに訓練済みの重みが一緒に読み込まれる。
ローディングには30分くらいかかるときがある。
model = VGG16(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None)
モデルを可視化してみた。
plot_model(model, to_file='vgg16.png', show_shapes=True)
事前の情報通り、Conv2D が13層、Dense が3層あることが見てとれる。
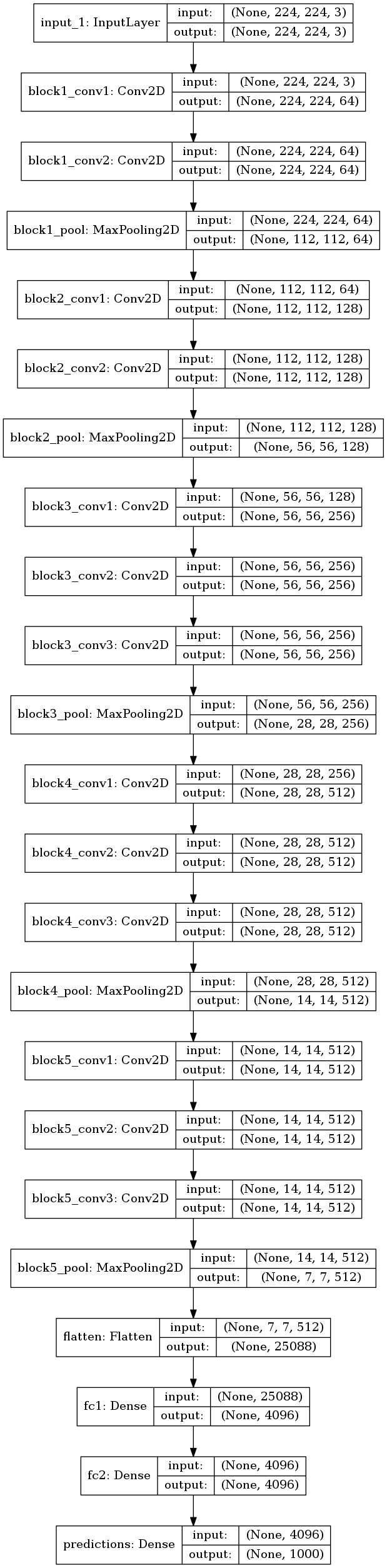
VGG16 Model
5. 画像認識
6枚の画像について認識させてみる。
まずはローカルに保存された画像をロードする。
images = [
'224x224/rabbit1.jpg',
'224x224/rabbit2.jpg',
'224x224/rabbit3.jpg',
'224x224/rabbit4.jpg',
'224x224/miku1.jpg',
'224x224/miku2.jpg'
]
x = np.zeros((len(images), 224, 224, 3))
for i in range(0, len(images)):
x[i] = load_image(images[i])
認識させてみる。下記のようにするだけでよい。
pred = model.predict(preprocess_input(x))
print('pred.shape={shape}'.format(shape=pred.shape))
# pred.shape=(6, 1000)
ここで preprocess_input というのが挟まっており、何者か気になる。
ヘルプを見ると、下記のように書いている(抜粋)。
>>> help(preprocess_input)
Help on function preprocess_input in module keras.applications.imagenet_utils:
preprocess_input(x, data_format=None, mode='caffe')
Preprocesses a tensor or Numpy array encoding a batch of images.
# Arguments
x: Input Numpy or symbolic tensor, 3D or 4D.
data_format: Data format of the image tensor/array.
mode: One of "caffe", "tf" or "torch".
- caffe: will convert the images from RGB to BGR,
then will zero-center each color channel with
respect to the ImageNet dataset,
without scaling.
さっき読み込んだ重みデータは Caffe 用として公開されているもののため、 Keras 上のテンソルとはチャネルの順番とかが違う。 そのため、RGB 形式で読み込んだ画像データを BGR 形式に変換し、 BGR それぞれについて平均が 0 になるようにする。
…ということか?
6. 認識結果
認識結果を表示するにも、便利な decode_predictions という関数が用意されている。
top = decode_predictions(pred, top=5)
for i in range(0, len(top)):
print('{i}:'.format(i=i))
for j in range(0, len(top[i])):
name, desc, score = top[i][j]
print(' {rank} {desc} {score:02.1f}%'
.format(rank=j+1, desc=desc, score=score*100))
結果を見る前に、decode_predictions について補足しておく。
この関数は内部で imagenet_class_index.json をダウンロードする。 この JSON ファイルには、予測結果ベクタの各インデックスに相当するクラス名が書かれている。
例えば np.argmax(pred[0]) を実行すると 330 が得られるので、
JSON の中から 330 のクラスを探すと次のように書かれており、
wood_rabbit と認識された、ということがわかる。
"330": ["n02325366", "wood_rabbit"],
では、認識結果を見てみる。
その1 ウサギ正面上

貰いもののウサギ写真である。
- wood_rabbit (ウサギ) 24.0%
- Angora (アンゴラウサギ) 23.4%
- hare (野ウサギ) 22.1%
- hamster (ハムスター) 17.2%
- guinea_pig (モルモット) 6.1%
ウサギ系の結果が TOP3 に並び、以下も似たような外見の動物が来た。 ちゃんと認識できたと言えよう。
その2 ウサギ側面

同じウサギ。
- hamper (洗濯カゴ) 11.2%
- computer_keyboard (PC キーボード) 8.2%
- hamster (ハムスター) 7.5%
- mouse (ネズミ) 7.1%
- tiger_cat (とら猫) 4.0%
残念な結果だ。 写真の6割ほどをケージが占めているからか、 1位は似たような構造を持つであろう洗濯カゴになってしまった。 確かに先入観無しにこの写真を見た場合、ケージの写真であると言えるかもしれない。 逆になぜ、我々はこの写真を見たときにウサギを撮ったものだと思うのだろう?
2位はキーボード。これもケージに引きずられてしまったのだろう。
耳がほぼ映っていないからか、ウサギ判定が下されなかった。
その3 ウサギ上面

これも同じウサギ。
- Angora (アンゴラウサギ) 73.2%
- wood_rabbit (ウサギ) 24.5%
- hamster (ハムスター) 0.7%
- hare (野ウサギ) 0.5%
- dishwasher (食器洗い機) 0.4%
正しく当てられた。
その4 ウサギ正面左

これも同じウサギ。
- wood_rabbit (ウサギ) 36.6%
- Angora (アンゴラウサギ) 28.6%
- hare (野ウサギ) 18.1%
- guinea_pig (モルモット) 1.6%
- hamster (ハムスター) 1.6%
色んな方向から撮った写真でもちゃんとウサギと認識してくれているみたいだ。 すごいぞ、VGG16。
その5 ミクさん 公式衣装 ver.

この作品は piapro から 竹籽さんの good morning をお借りした。
初音ミクさんの画像である。 これは VGG16 で学習したどのクラスともあまり近くない画像と思われる。 だから当然ニューラルネットがこれが何の画像が当てられるはずが無いのだが、 無理矢理分類させてみるとどうなったかというと、以下のようになった。
- bubble (泡) 14.6%
- comic_book (漫画) 12.0%
- oxygen_mask (酸素マスク) 10.0%
- stethoscope (聴診器) 3.6%
- shower_curtain (シャワーカーテン) 3.5%
1位の泡は何に反応したかわからない。 淡い色合いが泡っぽいとニューラルネットは思ったのかもしれない。 2位の漫画は、漫画、アニメ方面の絵と考えるとまあ当っている。
その6 ミクさん マジカルミライ2017 ver.

この作品は piapro から 駒鳥ういさん の ✨マジカルミライ✨ をお借りした。 勝手に 224x224 にトリミングさせて頂いた。
マジカルミライ 2017 のミクさんである。
- pinwheel (風車) 36.2%
- whistle (ホイッスル) 6.7%
- safety_pin (安全ピン) 5.3%
- comic_book (漫画) 4.5%
- stethoscope (聴診器) 3.8%
風車は少しわかる。 大きなリボンと広がるツインテールの造形の美しさは風車のそれに近いかもしれない。
やや面白いのは、その5のミクさんと共に判定されたものとして、 漫画の他に聴診器があることである。 ミクさんと聴診器が似ている、これはニューラルネットならではの発想ではないか。
7. まとめ
Keras で VGG16 を使って、画像認識をやってみた。 自分で用意した画像を分類させてみたところ、 VGG16 で学習済みのクラスについては適当に思える結果が得られた。
次回は Fine-tuning を試してミクさんを認識できるようにしてみたい。