Keras+VGG16で初音ミク画像認識
今回は VGG16 を使い Fine-tuning を試してみる。
これまでの Keras シリーズは以下。
- Keras+CNNでCIFAR-10の画像分類 その1
- CIFAR-10のPCA白色化/ZCA白色化
- Keras+CNNでCIFAR-10の画像分類 その2
- Keras+CNNでCIFAR-10の画像分類 その3
- Keras+VGG16でImageNetの画像分類
1. Fine-tuning
Fine-tuning (ファインチューニング)は、 学習済みのモデルの一部を流用することにより、そのモデルで 学習していないデータについても効率的に対応することができるテクニックである。 例えば、花の画像の特徴を学習し、花の分類をうまくできるモデルがあったとして、 それを流用し漫画キャラクターの分類をうまくできるモデルを作ることができる。
ただし、花とキャラクターでそれぞれの分類をするために有効な特徴量がある程度共通する場合に限る。だから極端な例を挙げると花の学習をしたモデルを使い、音声スペクトログラムの解析を行う Fine-tuning を試みたとしてもおそらくうまくいかない。
Fine-tuning では多層ニューラルネットの下層の重みを固定し、上層部のみを使って学習を行う。 VGG16 では典型的に、一番最後の畳み込み層と残りの全結合層のみを使い、 残りの重みは凍結 (freeze) させる。
学習済みのニューラルネットの下層は、画像のシンプルで汎用的な特徴を抽出するフィルタになっている。そのため、元々のモデルで学習した以外のデータに対しても、下層はうまく特徴量を抽出できるはずである。
一方、上層は、より複雑で訓練データに特化した特徴を抽出している。 そこで、学習済みのニューラルネットの下層はそのまま利用し、 上層は新しい訓練データで再度訓練してやれば元々学習していなかった画像に対しても 対応できるようになる。
Fine-tuning と似たテクニックに転移学習 (Transfer learning) というものがある。 これは全結合層のみを置き換えて再学習させる方法である。 全結合層の直前までで抽出できた特徴量 (ボトルネック特徴量)を取得し、 それから 3 層程度のニューラルネットにかけて学習させる。
2. 前準備
ではさっそく Fine-tuning の実験をしてみる。 今回、Keras を使い、VGG16 モデルの下層を固定し、上層のみを再学習させた。
実験の前にとりあえずライブラリをロードする。
# Numpy
import numpy as np
# Matplotlib
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
# Keras
from keras.layers import Dense, Dropout, Flatten
from keras.models import Model, Sequential, model_from_json
from keras.optimizers import SGD
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import plot_model
# Parameters
batch_size = 64
3. モデル構築
Keras では ImageNet の画像について学習済みの VGG16 モデルを一回でロードする ライブラリを提供している。
前回は全結合層を含めた全ての層の重みをロードしたが、
今回はどうせ捨てるので全結合層は対象から除いた。
全結合層を除く場合には VGG16 初期化時に include_top=False とする。
Fine-tuning をするモデルは、全結合層を取り去った VGG16 モデルの上に
新しい Sequential モデルを重ねることで構築する。
今回は練習で二値分類を行うことにした。一番最後の全結合層の出力は 1 次元とし
シグモイド関数で分類する。
また、下層をそのまま利用するというのは、下層の重みを固定することで実現する。
Keras では layer.trainalble = False とすることでその層の重みが固定され、
学習がなされなくなる。
def buildModel():
# Load VGG16 Model and its weights without the top layer
model_vgg16 = VGG16(include_top=False, weights='imagenet',
input_tensor=Input(shape=(224, 224, 3)),
input_shape=None)
# New fully-connected layers
model_top = Sequential()
model_top.add(Flatten(input_shape=model_vgg16.output_shape[1:]))
model_top.add(Dense(256, activation='relu'))
model_top.add(Dropout(0.5))
model_top.add(Dense(1, activation='sigmoid'))
# Concatenate VGG16 model and fully-connected layers
model = Model(inputs=model_vgg16.input, outputs=model_top(model_vgg16.output))
for i in range(0, 16):
model.layers[i].trainable = False
return model
model = buildModel()
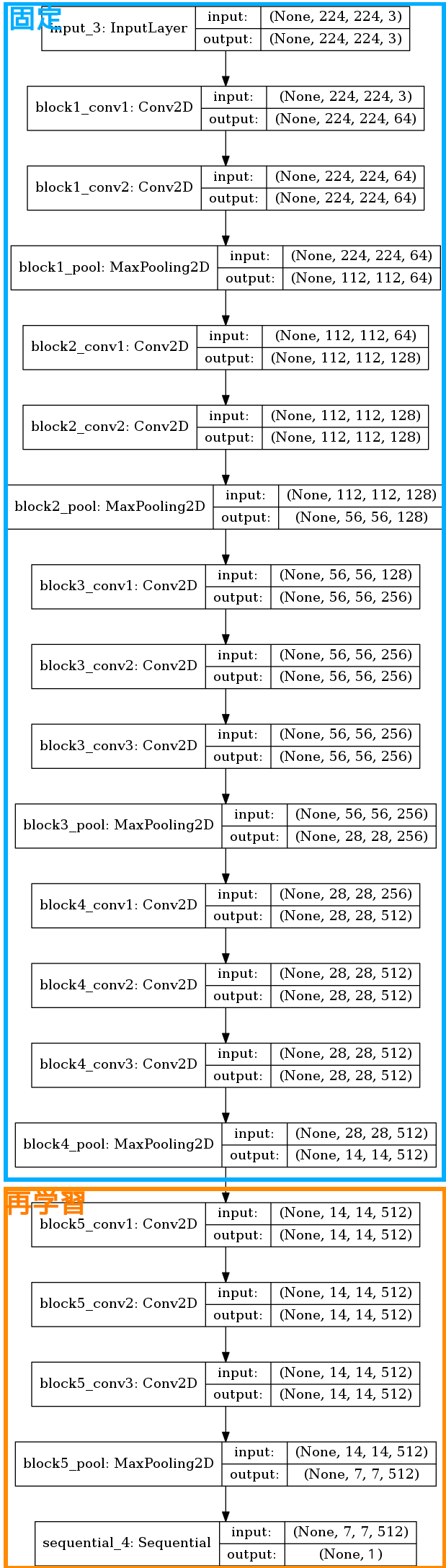
モデルを可視化してみた。 青枠で囲んだ層は重みを固定し、橙色の枠で囲んだ層は新しい学習データで訓練をする。
plot_model(model, to_file='vgg16-ft.png', show_shapes=True)
最後にモデルをコンパイルする。
パラメータ更新には学習係数を小さくした SGD を使うことが多いらしい。 更新される量を小さくすることで抽出された特徴量を尊重してあげるとのこと。
ちなみに、SGD って何だったっけと思ってしまったが、 Stochastic gradient descent すなわち確率的勾配降下法である。
自戒をこめて再度勉強すると、 誤差関数を重み $ \mathbf{w} $ の関数 $ E(\mathbf{w}) $ とおいたとき、 次の式のように重みを更新する方法のことだった。
\[\mathbf{w}^{(t+1)} = \mathbf{w}^{(t)} - \epsilon \nabla E_n\]ここで $ \epsilon $ は学習係数、 $ E_n $ はあるサンプル $ n $ について計算される誤差である。
model.compile(loss='binary_crossentropy',
optimizer=SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
4. 訓練
初音ミクさんと鏡音リンさんの画像について学習させ、正しく区別できるようにしたい。
学習データは独自の方法で収集した。私の手元には初音ミクさん画像 12,000 枚強と 鏡音リンさん画像 1,200 枚強がある。
このうち、今回用いたのは以下の通り。
- 訓練データ: ミクさん、リンさん 各 1,100 枚
- バリデーションデータ: ミクさん、リンさん 各 110 枚
世界的アイドルであるミクさんと比べると、リンさんの画像が集まりにくいため、 リンさんに合わせてミクさんの画像はランダムに抽出した。
リンさんについてはレンさんとセットになっていることも多く、 さらに枚数を減らしてしまった。 途中で面倒になったので、一部レンさんが写っていても許容した。 リンさんもレンさんも似たような特徴を持っていると思うので、ミクさんの区別するためには 支障無いと予想した。
訓練セット、バリデーションセットの読み込みは Keras のライブラリを使うことで簡単に書ける。
各データは以下のようなファイル構造で保存してある。
$ tree
/mnt/dataset
├── train
│ ├── miku
│ │ ├── 109992_p0_master1200-1.png
│ │ ├── 114975_p0_master1200-1.png
│ │ ├── 136417_p0_master1200-2.png
│ │ └── sm32070133-072-1.png
│ └── rin
│ ├── 65070740_p0_master1200-2.png
│ ├── 65088455_p0_master1200-2.png
│ ├── 65188035_p0_master1200-2.png
│ └── sm25584077-075-3.png
└── validate
├── miku
│ ├── sm32070133-073-1.png
│ ├── sm32070133-073-2.png
│ ├── sm32070133-077-3.png
│ └── sm32711991-192-2.png
└── rin
├── sm25584077-077-1.png
├── sm25584077-078-1.png
├── sm25584077-078-2.png
└── sm25584077-165-3.png
Keras ではディレクトリ名を見て分類済みのデータセットを作成してくれる。
DIR_TRAINING = '/mnt/dataset/train/'
DIR_VALIDATION = '/mnt/dataset/validate/'
datagen_train = ImageDataGenerator()
generator_train = \
datagen_train.flow_from_directory(DIR_TRAINING,
target_size=(224, 224),
batch_size=batch_size, class_mode='binary')
datagen_validate = ImageDataGenerator()
generator_validate = \
datagen_validate.flow_from_directory(DIR_VALIDATION,
target_size=(224, 224),
batch_size=batch_size,
class_mode='binary')
いよいよ訓練させる。いつも通り実行するだけである。 3時間かかった。
hist = model.fit_generator(generator_train,
steps_per_epoch=1100 // batch_size,
epochs=20,
validation_data=generator_validate,
validation_steps=110 // batch_size)
訓練の履歴は次のようになった。 20 エポックしか訓練していないが、バリデーション損失が横這いになっているので このままの手法だとほぼ限界の性能に達してしまっていると思われる。
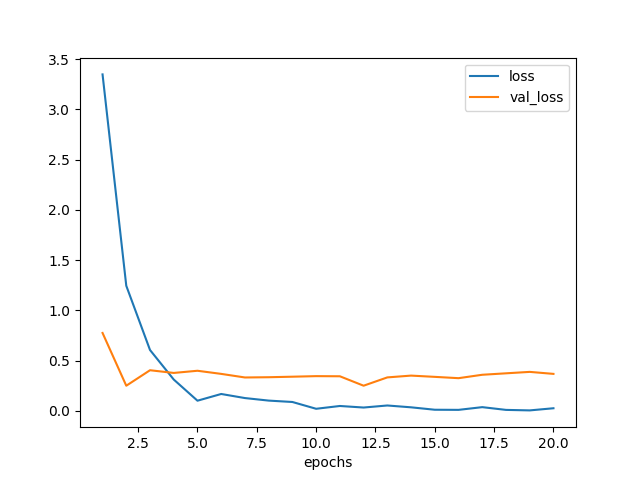
図 4.1. Fine-tuning による学習曲線
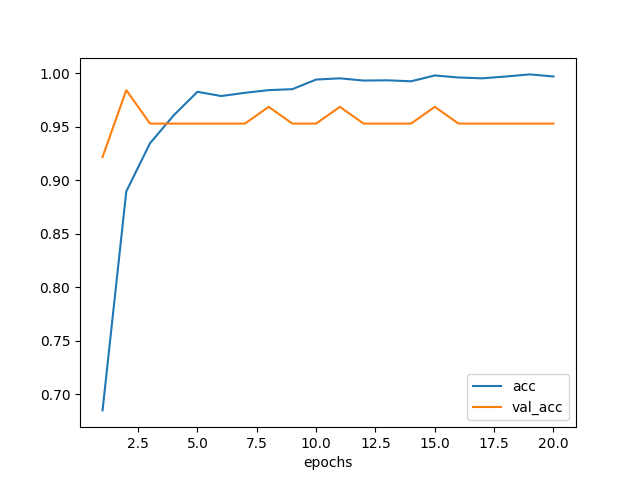
図 4.2. Fine-tuning による精度推移
5. 学習結果
上記データセットに無い画像を使い、モデルの判定結果を見てみた。
以下では初音ミクさんと鏡音リンについて 4 枚ずつ拾ってきた計 8 枚の画像を ニューラルネットに見せてみた。 結果は 8 枚中 7 枚について正しく区別でき、まずまずの性能と感じた。
def load_image(filename):
img = image.load_img(filename, target_size=(224, 224))
return image.img_to_array(img)
images = [
'224x224/miku1.jpg',
'224x224/miku2.jpg',
'224x224/miku3.png',
'224x224/miku4.jpg',
'224x224/rin1.jpg',
'224x224/rin2.jpg',
'224x224/rin3.jpg',
'224x224/rin4.jpg',
]
x = np.zeros((len(images), 224, 224, 3))
for i in range(0, len(images)):
x[i] = load_image(images[i])
pred = model.predict(x)
print('pred.shape={shape}'.format(shape=pred.shape))
# pred.shape=(8, 1)
for img, y in zip(images, pred[:,0]):
print('{img} {y:.5f} {pred}'
.format(img=img, y=y, pred='miku' if y < 0.5 else 'rin'))
では判定結果について確認する。
その1 ミクさん 正解!

print('{pred:.5f}'.format(pred=pred[0,0]))
# 0.00000
⇒かなり初音ミク
この作品は piapro から 竹籽さんの good morning をお借りした。
その2 ミクさん 正解!

print('{pred:.5f}'.format(pred=pred[1,0]))
# 0.00000
⇒かなり初音ミク
この作品は piapro から 駒鳥ういさん の ✨マジカルミライ✨ をお借りした。
その3 ミクさん 正解!

print('{pred:.5f}'.format(pred=pred[2,0]))
# 0.00000
⇒かなり初音ミク
この作品は piapro から あごなすびさん の 初音ミクv4x をお借りした。
その4 ミクさん 正解!

print('{pred:.5f}'.format(pred=pred[3,0]))
# 0.00000
⇒かなり初音ミク
この作品は piapro から (kenji) の マジカルミライ2016 をお借りした。
その5 リンさん 不正解

print('{pred:.5f}'.format(pred=pred[4,0]))
# 0.32799
⇒どちらかといえば初音ミク
ニューラルネットは初音ミクとして判定したが、 この画像は鏡音リンのものであるから不正解である。
訓練データは MMD 動画から切り出した画像が多かったため、 強くデフォルメされた画像の判定が苦手になったのかもしれない。
この作品は piapro から Yおじさん の ねんどろいど 企画 をお借りした。
その6 リンさん 正解!

print('{pred:.5f}'.format(pred=pred[5,0]))
# 1.00000
⇒かなり鏡音リン
この作品は piapro から akinoさん の りんちゃん疾走! をお借りした。
その7 リンさん 正解!

print('{pred:.5f}'.format(pred=pred[6,0]))
# 1.00000
⇒かなり鏡音リン
この作品は piapro から nezukiさん の リンリン をお借りした。
その8 リンさん 正解!

print('{pred:.5f}'.format(pred=pred[7,0]))
# 1.00000
⇒かなり鏡音リン
この作品は piapro から ちづさん の 届くといいなぁ をお借りした。
グレイスケールだったら
正しく判定されるのだろうか? ここまでのテスト画像を見るだけならば、 青が使われた画像はミクさん、黄が使われた画像はリンさんと判断する、という アルゴリズムでも十分判別できてしまいそうに思えたので少し不安になった。
そこで先ほどの画像をグレースケールに変換した場合にどう判定されるか確認してみた。
以下が確認結果である。 $ y < 0.5 $ ならばミクさん判定、 $ y > 0.5 $ ならばリンさん判定。
すごい、今度は全て正解した。 グレースケールで正しく判定できるということは、やはり姿も見て特徴量を抽出できていると思われる。

|

|

|

|
| $ y = 0.00000 $ | $ y = 0.41954 $ | $ y = 0.00000 $ | $ y = 0.01366 $ |

|

|

|

|
| $ y = 0.70458 $ | $ y = 0.99999 $ | $ y = 0.99866 $ | $ y = 1.00000 $ |
$ y $ の値を見ると、ミクさん判定の基準にはやっぱりツインテールが有効なのだろうか?
ツインテ特徴量。実によい特徴量ではないか。
6. まとめ
VGG16 モデルを使い Fine-tuning の実験をした。 バリデーションセットに対する判定精度は 95% あるし、 テスト用に用意した画像についても 16 枚中 15 枚ちゃんと判定できたので、 それなりに満足している。
3 個以上のクラスに対する判定もやってみたい。
この実験のために、ミクさんとリンさん(とルカさんも少し)の画像を 13,000 枚も集めた。 彼女らの画像を延々と仕分ける作業を通し、自分にとってミクさんはどのような存在なのか、 リンさんのかわいさの本質は何かといった、よりメタな学習を私の中で進められた。
高速手動仕分けツールとか、動画から画像を生成するツールとか作ったので、 これはまた別途公開する。
7. 参考
- Building powerful image classification models using very little data
- VGG16のFine-tuningによる犬猫認識 (2) - 人工知能に関する断創録
- Keras / Tensorflowで転移学習を行う
- 画像の前処理 - Keras Documentation
- Keras のモデルと学習結果を保存して利用する - m0t0k1ch1st0ry
- pythonによる画像処理(Pillow)
8. ソースコード
# Numpy
import numpy as np
# Matplotlib
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
# Keras
from keras.layers import Dense, Dropout, Flatten
from keras.models import Model, Sequential, model_from_json
from keras.optimizers import SGD
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import plot_model
batch_size = 64
def buildModel():
# Load VGG16 Model and its weights without the top layer
model_vgg16 = VGG16(include_top=False, weights='imagenet',
input_tensor=Input(shape=(224, 224, 3)),
input_shape=None)
# New fully-connected layers
model_top = Sequential()
model_top.add(Flatten(input_shape=model_vgg16.output_shape[1:]))
model_top.add(Dense(256, activation='relu'))
model_top.add(Dropout(0.5))
model_top.add(Dense(1, activation='sigmoid'))
# Concatenate VGG16 model and fully-connected layers
model = Model(inputs=model_vgg16.input, outputs=model_top(model_vgg16.output))
for i in range(0, 16):
model.layers[i].trainable = False
return model
model = buildModel()
plot_model(model, to_file='vgg16-ft.png', show_shapes=True)
model.compile(loss='binary_crossentropy',
optimizer=SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
DIR_TRAINING = '/mnt/dataset/train/'
DIR_VALIDATION = '/mnt/dataset/validate/'
datagen_train = ImageDataGenerator()
generator_train = \
datagen_train.flow_from_directory(DIR_TRAINING,
target_size=(224, 224),
batch_size=batch_size, class_mode='binary')
datagen_validate = ImageDataGenerator()
generator_validate = \
datagen_validate.flow_from_directory(DIR_VALIDATION,
target_size=(224, 224),
batch_size=batch_size,
class_mode='binary')
# 3 hours
hist = model.fit_generator(generator_train,
steps_per_epoch=1100 // batch_size,
epochs=20,
validation_data=generator_validate,
validation_steps=110 // batch_size)
plt.clf()
plt.xlabel('epochs')
plt.plot(np.arange(1, len(hist.history['loss'])+1),
hist.history['loss'], label='loss')
plt.plot(np.arange(1, len(hist.history['loss'])+1),
hist.history['val_loss'], label='val_loss')
plt.legend()
plt.savefig('mikurin1_loss.png')
plt.clf()
plt.xlabel('epochs')
plt.plot(np.arange(1, len(hist.history['acc'])+1),
hist.history['acc'], label='acc')
plt.plot(np.arange(1, len(hist.history['acc'])+1),
hist.history['val_acc'], label='val_acc')
plt.legend()
plt.savefig('mikurin1_acc.png')
# Save
open('vgg16.json', 'w').write(model.to_json())
model.save_weights('mikurin1_weights.h5')
# Restore
# model = model_from_json(open('vgg16.json').read())
# model.load_weights('mikurin1_weights.h5')
def load_image(filename):
img = image.load_img(filename, target_size=(224, 224))
return image.img_to_array(img)
images = [
'224x224/miku1.jpg',
'224x224/miku2.jpg',
'224x224/miku3.png',
'224x224/miku4.jpg',
'224x224/rin1.jpg',
'224x224/rin2.jpg',
'224x224/rin3.jpg',
'224x224/rin4.jpg',
'224x224/miku1-grayscale.jpg',
'224x224/miku2-grayscale.jpg',
'224x224/miku3-grayscale.png',
'224x224/miku4-grayscale.jpg',
'224x224/rin1-grayscale.jpg',
'224x224/rin2-grayscale.jpg',
'224x224/rin3-grayscale.jpg',
'224x224/rin4-grayscale.jpg'
]
x = np.zeros((len(images), 224, 224, 3))
for i in range(0, len(images)):
x[i] = load_image(images[i])
pred = model.predict(x)
print('pred.shape={shape}'.format(shape=pred.shape))
# pred.shape=(8, 1)
for img, y in zip(images, pred[:,0]):
print('{img} {y:.5f} {pred}'
.format(img=img, y=y, pred='miku' if y < 0.5 else 'rin'))
せっかくだからグレースケールにするプログラムも貼っておく。
import os
from PIL import Image
def grayscale(src, dest):
print('src={src}, dest={dest}'.format(src=src, dest=dest))
img = Image.open(src)
gimg = img.convert('L')
gimg.save(dest)
def main():
images = ['224x224/miku1.jpg', '224x224/miku2.jpg',
'224x224/miku3.png', '224x224/miku4.jpg',
'224x224/rin1.jpg', '224x224/rin2.jpg',
'224x224/rin3.jpg', '224x224/rin4.jpg']
for src in images:
name, ext = os.path.splitext(src)
dest = '{name}-grayscale{ext}'.format(name=name, ext=ext)
grayscale(src, dest)
if __name__ == '__main__':
main()